CS639 – class 4
Handout: CS639 Recursive XML Example
Join the google
group! See invitation in your email account as listed in your .forward file on
our system.
HW1 due, have set up forum for pa1a, also added more files to dir, including sample output for Scan1. Q’s on pa1a?
First steps for pa1a: (like readme.txt in pa1a)
- transfer pa1a dir or pa1a.zip to your PC, say to c:\cs639\pa1a
- “ant build” as first check, “ant test00” runs DumpMethods on Grid
- In eclipse, create a Java project, and choose the option "Create project
from existing source", and browse to your directory. Make sure you are using Java 1.6.
(You may need to fix the “Default output folder” from pa1a/bin to pa1a/build/classes.)
Also--
- Check that the directory structure is right: build/classes/…
- In project’s Properties>Java Build Path>Source, you should see Source folders “pa1a/src”, and at the bottom under “Default output folder: “pa1a/build/classes”. In the Package Explorer, see both src and input directories, plus build.xml and README.
- As a check, delete the project, keeping files, and recreate it—useful way out of problems.
Note: we are doing this project “the hard way”, from basics, so you can see the nitty-gritty details. You could use the powerful JAXB package to convert Java objects to XML, but then you would have to create objects for each construct, an unnecessary job. Another approach that is more practical is using JDK6’s XMLStreamWriter, part of the StAX API, (“streaming parser” on reading side) which became available in Java since our book was written. You can use it if you want. Several tutorials exist on the web.
Looking at the
handout on Recursive XML:
Note JSON can’t do recursive data structures.
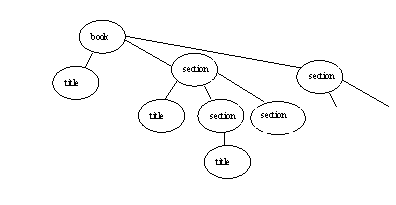
A section has a title, followed by <p>, then possibly a figure (or figures?), the possibly sections.
The figure has a title, then an image. Every time you look at an image, you have a source attribute.
Picture of tree of elements: book at top, children below, sections within sections, …
Partial picture:
The DTD, schema: specify structure patterns.
The DTD entry for an element has form:
<!ELEMENT name contentspec>
The content spec can be: (#PCDATA) or EMPTY or ALL or a “content model” describing how the child elements are organized. There is another possibility for “mixed content” that we can look at next time.
This content model can be a sequence of comma-separated,
decorated element tagnames, with parentheses for
grouping, and *, +, and ? indicating
how many can show up. The whole thing is inside parentheses.
On the handout , we have:
<!ELEMENT section (title, p, (figure, p)*, section*)>
The easiest content spec is just (#PCDATA), i.e., CharData.
<!ELEMENT title (#PCDATA)>
Note that although an element can have a “content model” in a DTD, that description does not have the power to say that there should be a number represented by the CharData, as in <price>10.99</price>.
XML Schema:
- in XML !
- allows us to build up type definition from parts:
ex: Image Type – how it has attribute “source”
Figure Type – has child element of ImageType.
- allows a Section Type defined with child element – Section Type.
- All field-level types in this example are just strings (common).
- But in general, supports useful types for element content, such as <xsd:decimal>, unlike DTDs
Look at book.xsd on handout and see the build-up of types, familiar to programmers.
We can reorder the various type definitions. We can also reorder the lines of the DTD.
Note only one top-level “xsd:element” element under the xsd:schema element, for the root element named book. All the rest fall under this, of various types given by the xsd:complexType elements. Somewhat like a Java class with all its fields, themselves having type definitions.
The type of the book element has no name; it’s an “anonymous type”. We could give it a name if we wanted, with a little more text. But since it shows up only in one place here, it doesn’t need a name.
The schema does not describe exactly the same structures as the DTD. The schema only allows one figure per section, while the DTD allows additional (figure, p) pairs, so a section could have, say, 3 figures as long as each is followed by a p. We could modify the schema to match the DTD this way, but it would require us to use another xsd element type, the <xsd:group> element, to form the (figure, p) group that itself is allowed to repeat.
We drew a tree of elements to show its structure, described by DTD content models and XML Schema complex-type declarations.
Note the “extra” element declaration in book.dtd:
<!ELEMENT c (#PCDATA)>
where there are no <c>’s in book.xml or use of c in other element declarations in the DTD. This is harmless, because a declaration only comes into play if there is a <c> element in the document. There’s no requirement that they all are related, or all used. In fact, the same DTD can be used for documents with different root elements, so the following is valid
<?xml version="1.0"?>
<!DOCTYPE c SYSTEM "book.dtd">
<c> foo </c>
Though this looks stupid, this capability can be used in serious ways. For example, we might have one DTD to describe both requests and response messages, one with root element request and the other with root element response, but common subtrees.
Similarly, in the XML schema, we can add a top-level c element:
<xsd:element name="c"
type="xsd:string"/>
and then a simple <c>-rooted document is valid:
<?xml
version="1.0" encoding="ISO-8859-1"?>
<c xsi:noNamespaceSchemaLocation="book.xsd"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
foo
</c>
Note that the XML schema linkage does not specify the root element name like the DTD does.
book.xsd is an example of XML schema for structured data, no “mixed content”, i.e. no semi-structured data.
Mixed Content:
semi-structured data
Mixed content, or “semi structured” data: not in our book.xml. Need to change it a little. Suppose a <p> element could look like this:
<p> <c> The </c> most <c> important </c> … <web> … </web> </p>
A p element can have text between any number of occurrences of <c> and <web> markup. That’s the DTD idea of mixed content, expressed by:
<!ELEMENT p (#PCDATA|c|web)*>
allows c and other web element anywhere, in any number, inside a p element. No elements within elements, however. The star is required if you use the |.
From the standard:
|
|
::= |
||
So we see that the simple <!ELEMENT p (#PCDATA)> is officially “mixed content”, although used all the time for structured data.
XML Schema: has a different idea of mixed content, unfortunately.
Reading; Start Chap 16 on XPath, to pg.
758.