CS639 Class 05 XPath, more on UTF-8,
TestXPath: handout: KBOS.xml
pa1a due Wed. night: questions?
XML Schema & Semi-Structured data.
XML schema has a different definition of a mixed content than DTD.
- much more restrictive than DTD;
- can add mixed = “true” to the complexType element. All this means that ordinary text can show up between the elements, otherwise constrained as before (without mixed=”true”).
- Thus we can’t allow markup like arbitrary <c>’s and <web>’s as above
Ex we can do in XML Schema: “form letter” where we want just one name element and one amt element—can handle this easily in XML Schema.
<letter> Dear <name> Joe </name> ,
You have just won <amt> 1000 </amt> dollars.
</letter>
<?xml
version="1.0"?>
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<xsd:element name="letter">
<xsd:complexType mixed=”true”>
<xsd:sequence>
<xsd:element name="name type="xsd:string"/>
<xsd:element name="amt"
type="xsd:string"
/>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
Of course it’s even easier in a DTD:
<!ELEMENT letter
(#PCDATA|name|amt)*>
But this does not specify just one name followed by one amt. All you can specify in a mixed-content DTD content spec is which elements can appear, not their order or number of occurrences.
Note that Harold warns against use of mixed content in data-oriented apps, at top of pg. 19. It is very useful for XHTML, and other document-oriented apps.
ANY Good XML Content for an element
We can go further in the direction of free-formed XML content, beyond “mixed”--
Elements can have any well-formed XML as contents in DTD or XML Schema.
Again let us free up the contents of the p elements of book.xml, now to any well-formed XML.
DTD:
<!ELEMENT p ANY>
XML Schema: set up type for p elements:
<xsd:complexType
name=”PType”>
<xsd:sequence>
<xsd:any processContents = “skip” ß”any”
for XML Schema
minOccurs=”0” maxOccurs=”unbounded”/>
</xsd:sequence>
</xsd:complexType >
Now put
<xsd:element name=”p” type=“PType”/> in Section def.
Important extensibility capability: we can package up any XML in a document generally constrained by a vocabulary.
The embedded XML could have its own vocabulary (ex. XHTML). You have to use namespaces to differentiate multiple vocabularies (so we won’t pursue this now.)
- see XML Schema Primer, sec 5.5 is linked under Resources.
Stylesheets: just the idea
XML is used to describe data, not its presentation (to the user).
![]()
![]() XML HTML
XML HTML
(holds the data) stylesheet presentation
Stylesheet:
- how to present data;
- CSS simple, too limited (skip)
- XSL – full power of functional programming language = XSLT + XSL–FO
o XSLT is the processor
o XSL stylesheets say what to do
XSLT and its stylesheets can transform XML to other XML also, so it’s not just for UI
Can JDK do XSLT ? Sure….
Start on XPath Basics
Read the first 6 pages of Chap. 16 for now.
XSL uses XPath to locate data in XML input. So do other tools.
XPath is a simple query language for XML. It is sort-of equivalent to SQL for DB data, if SQL could only read tables and return row ids, not the actual data. It’s like the first part of a SQL query where the query processor locates the results in the data.
XQuery is more powerful, can compose new XML rather than just find things in XML. It really is like SQL queries. Not widely used however.
Look at the tree of element of elements (other things as well can be there)
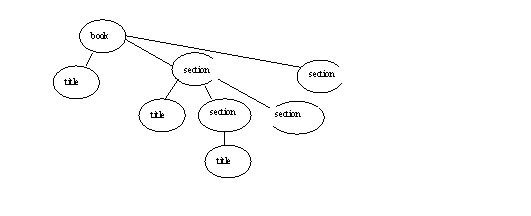
Idea of path: /book/section/title – path to the element down from the root
XPath Query: find the nodes that match a path description
1) /book/section/title query has results: 2 nodes, the 2 title elements of the two top level sections
2) /book/section/section/title as query result has maybe 4 titles of second-level sections.
Find all title elements, user XPath //title
TestXPath: use the power of the JDK to process XPath queries
Note that XPath is not a standalone tool, that is, there is no standard “XPath query tool” like SQL monitors for SQL. XPath is used in conjunction with some other tool, such as an XSL processor or a database tool that can read XML to get data for tables. Since the JDK has full XPath support, we can write our own tool, and that is what I have done with the TestXPath program. You can read this one-page program, but we are not covering the JDK API in use there yet.
Our XPath processing program – TestXPath program, in $cs639/xpath, linked from the class web page under Resources, XPath, along with the W3C Recommendation (“standard”)
Ex: java TestXPath clocks.xml
Enter xpath expression: …
See README
displays
- all the paths of selected nodes.
- string value of the first node selected
o See Table 16.1 of Harold, pp. 757-758, for definition of “string value”
The JDK has XPath support. It can return “nodes” to your program, one for element (or other thing) it locates in the XML. I’ve written a little program TestXPath that will run XPath queries on a given XML file, like this:
java TestXPath book.xml
Enter XPath expression:
/book/section <--you enter the XPath expression
Using file book.xml, xpath =
/book/section
Report of node.toString's and
paths of all hits:
[section: null] /book/section
[section: null] /book/section
Given: well-formed XML document, after resolution of entity references like < etc. (and CDATA sections, but we’re ignoring them for now).
No DTD or schema is needed, so we are working with the document itself. Great tool for schema-less XML. Without a schema, you have no assurance that the structure is stable, so XPath is your best bet for finding answers even if a new level has been added to the tree.
Handout: local weather info in XML at:
http://www.weather.gov/xml/current_obs/KBOS.xml (Logan airport)
First line of doc shows char encoding is ISO-8859-1, surprising, old-fashioned.
We can use XPath to dig out particular info:
/current_observation/temp_f or /temp_c this would be the XPath for F or C as temperature.
In fact, the filename argument for TextXPath can take a URL
Try, using file KBOS.xml in $cs639/xpath:
cd $cs639/xpath
java
TestXPath KBOS.xml
Enter
XPath expression: /current_observation/temp_f
Report
of node.toString's and paths of all hits:
[temp_f:
null] /current_observation/temp_f
Content
of first hit:
43.0
Using
URL:
java
TestXPath http://www.weather.gov/data/current_obs/KBOS.xml
Report
of node.toString's and paths of all hits:
[temp_f:
null] /current_observation/temp_f
Content
of first hit:
43.0
to get the current Boston temperature in F
We consider the XML as a tree of elements, attributes, etc., all called nodes. Note that the XML spec itself never talks about nodes, just elements, attributes, …, and CharData, entity refs, etc.
Consider another kind of object in XML tree rep: text node, in boxes here: In simple cases, the contents of a text node is just the character data contents (with <, not < etc.) of an element. XPath processing always follows XML parsing, during which < is turned back into <.
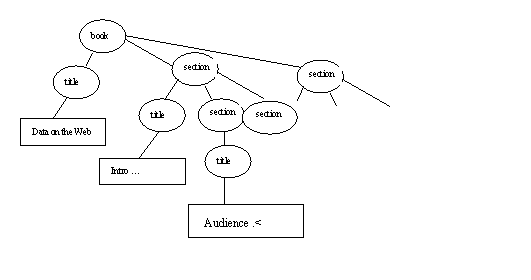
Here the first section title element has been changed to <title>Audience <</title> to give an example of an entity in element content. The entity is resolved in the XPath text node. Note the < in the text node, not <
(In fact, the bits of “white space” between element tags provide additional text nodes, but let’s not worry about this yet.)
Look at an element
/book/section/title – path to the element
XPath: find the nodes that match a path description
3) /book/section/title query has results: 2 nodes, the 2 title elements of the two top level sections
4) /book/section/section/title as query result has maybe 4 titles of second-level sections.
Find all title elements, user XPath //title
Find the first section of book:
/book/section[1] yields one section element that is the first section of the book.
Document order and the XPath node tree
Note that the child nodes of a certain node in the XPath node tree are in a certain order, which makes the whole tree of elements ordered. The resulting ordering of elements by depth-first traversal is known as document order, and follows the order of elements in the textual XML. The other nodes in the XPath node tree are in all cases attached to a certain element. The order of attributes for an element is not fixed in the XPath node tree, so we say an element node has a set of attribute nodes. This is alluded to on Harold, pg. 759, first paragraph. So the whole collection of nodes is not fully ordered, but is still referred to as in “document order” following the depth-first traversal of the node tree.
For each element node, attribute nodes precede child element nodes, as in the textual XML. Text nodes for an element node (vs. child nodes) are in the order determined by the textual XML.
/book/section[title = “Introduction”] yields one section element that has a title = “Introduction”
Here the XPath before the [] selects all the top-level section nodes. For each of these, the [title …] is a predicate filtering out some of those nodes. The “title” inside the [] is the relative XPath from an already selected node (i.e. a top-level section node) and it gets to corresponding title of that section node, which needs to match the “Introduction” string to pass the predicate test. The result is a section node.
See Examples on pg 754 on Weather Data. Here is a partial graph—you need to add to it to see everything for the queries. Note that this is quite different from the weather data we looked at earlier (KBOS.xml).
16
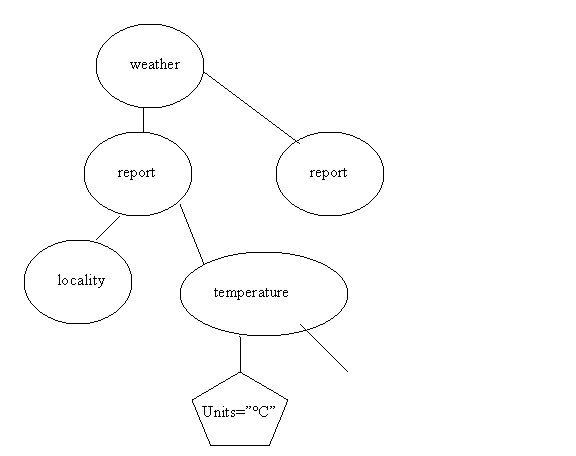
/weather/report[1] 1 report node, Block I.
/weather/report/temperature 2 temperature nodes
/weather/report [locality = “
/weather/report [locality = “
This gives you direction node of the wind node for Block Island’s report.
Localities where wind is NE:
/weather/report[wind/direction = “NE”]/locality
localities having the same temperature as
/weather/report/[temperature = /weather/report[locality=”
/weather/report/[temperature < 20 and wind/direction=”NE”]
or
/weather/report/[temperature < 20]/wind[direction=”NE”]
Query on attributes: find temperature elements with units attribues:
/weather/report/temperature[@units]
All temperature nodes under report at any level--
/report//temperature
All elements: //*
All attributes //@*
All attributes named units: //@units
All textnodes: //text()
All textnodes of temperature elements: //temperature/text()
Note that weather.xml is in $cs639/xpath, so you can try these out.