CS639 – class 14
Handout on DOM and namespaces
Last time: intro example for DOM
After Midterm: REST
Web Services
Read Webber et al, Chap 1-3: background, we’ve covered the underlying Web technology already.
Then start studying Chap 4, the CRUD service for coffee orders, first real example. I’ll supply a Java project for this.
First task: write a client for this service, say deployed at http://sf06.cs.umb.edu:11600/orderService, with schema for messages available at
http://sf06.cs.umb.edu:11600/orderService/OrderService.xsd.
From client viewpoint: Order a coffee:
POST XML for order to http://sf06.cs.umb.edu:11600/orderService/rest/order
get back XML for order with id filled in, say order 22, status = PREPARING
This means this order’s resource is /orderService/rest/order/22.
Find out the order status:
GET to /orderService/rest/order/22, to get the current “resource” there, see same old status in the XML response
Separately, the admin sends POST to .../rest/poke: make oldest order ready.
GET to /orderService/rest/order/22, to see if it’s ready, see status=READY in the XML, time to pick it up.
Nifty way: use JAXB to turn provided schema into Java objects for client to use.
The service can also provide JSON if we want.
Chap 10: Just one example to show use of DOM with Namespaces
Example 10.5 SimpleSVG: See SimpleSVG1.java in $cs639/dom and on handout.
Creates doc with default namespace (bug referred to on pg. 504 has been fixed):
<?xml
version="1.0" encoding="UTF-8"
standalone="no"?>
<!--An
example from Chapter 10 of Processing XML with Java-->
<?xml-stylesheet
type="text/css" href="standard.css"?>
<svg
xmlns="http://www.w3.org/2000/svg"><desc>An example from
Processing XML with Java</desc></svg>
Recall we are not trying to use DTDs and namespaces together, so we drop the svgDOCTYPE creation and just put null in createDocument’s third arg, as done in SimpleSVG1.java.
This program shows another way to get started on building a DOM document: get a DOMImplementation object from the builder, and use it to call createDocument, with arguments specifying the root element tagname and namespace. This one call creates both the Document and the Element for the root element, i.e., the minimal valid DOM tree. Then we get the Element for the root element from the new Document and use it the same way as before in Example 5.6.
Using NS: now use doc.createElementNS() with NS URI arg.
Handout: like SimpleSVG, but with namespace prefixes. All you need to do is add them on the names. These methods take qualified name arguments.
This is made clear for createElementNS on pg. 897, and createDocument, pg. 900, but less clear for getElementsByTagName, pg. 901. There is another method getElementsByTagNameNS, but we can use the simpler one.
DOMReader.java: this shows how to read in an XML document with prefixed namespaces and use a NS-aware tagname-search on it, that is, finding all the nodes with a certain localName in a certain NS.
Note the two feature settings used here:
· one to set the “coalescing” feature, which puts CDATA text (after “resolution”) into the Text nodes along with the normal text. More on this later, with CDATA example. This is off by default.
· another to set namespace-aware, so DOM will maintain NS info on elements and attributes for us, and match up names based on NS and localName. This is off by default.
These two are both good settings in general for reading into DOMs for data-centric apps. However, if you want to use XPath on the DOM, you should leave namespace awareness off, unless you want to set up a NamespaceContext object to do the prefix-URI mapping for the names in the XPath query itself.
Chapter 9 DOM
DOM Modules: can skip, trusting JDK to have the important
support
Optional notes
- note that traversal and range are not in J2SE 5.0
Leaves 4 modules that are data-related (so we’re interested) & in J2SE5.0 and 6.0 (so we can easily use them)
Core, XML, Events and MutationEvents.
Add to this list Load-Save module, new with DOM3 and in JDK 6.0 and used in FibonacciEx.java discussed above.
Pg. 437: hasFeature() method of DOMImplementation interface provides info on features of a specific DOM implementation. This is an interface with a funny name, since an “implementation” usually means a concrete class.
Example 9.1 Java 6 has “DOMImplementation” as an interface, but no XMLDOMImplementation class, needed by this program. Note warning sign: “import oracle….” This class is Oracle-specific.
How can we get an object like this, so we can ask about features? From a Document or a DocumentBuilder.
See Pg 897 DOM Document API – we can ask a Document for a DOMImplementation. We could reimplement this example (Ex 9.1) and find the features of the software.
See pg. 912 JAXP DocumentBuilder API—we can ask a DocumentBuilder for it too.
DOMImplementation API: pg. 900 See createDocument, another way to start a Document.
End of optional
notes
App-specific DOMS—can
skip.
Trees – DOM Data
Model
- idea of “Nodes”, similar to XPATH nodes.
- Note that SAX did not use this terminology and the XML 1.0 spec does not use the term NODE.
- SAX has events reporting simple strings, etc, no objects that hold stuff. (Well, it does give us the attributes in a special object, but it’s not at all node-like.)
DOM tree:
- the official tree of nodes
- has various other nodes associated with certain tree nodes: attributes are the main case here
- disconnected nodes.
Page 441: 12 kinds of nodes for DOM
The first 6 listed correspond to XPATH nodes.
The document NODE corresponds to XPATH root Node.
For DOM: 12 kinds of Nodes
For XPath: 7 kinds of Nodes.
See pg. 760 for discussion of XPath vs. DOM
|
DOM node |
Corresp. XPath node |
|
Document node |
Root node |
|
Element node |
Element node |
|
Text node (includes CDATA text if the coalescing feature is on) |
Text node (but includes CDATA, entity text) |
|
Attribute node |
Attribute node |
|
PI node (skip) |
PI node |
|
Comment node |
Comment node |
|
CDATA node (missing if coalescing is on) |
--- Absorbed into text node |
|
Document type node |
|
|
Notation node (skip) |
|
|
Document fragment node (skip) |
|
|
Entity node (skip) |
--- Resolved entities are in Text nodes |
|
Entity Reference node (skip) |
|
Note: Namespace Nodes are in XPath but not in DOM. In DOM, namespace information for nodes is available via Node methods getNamespaceURI and getPrefix. See pg. 904. This setup is convenient for programmers—DOM has digested the whole document and determined from the various xmlns=... attributes what NS pertains to each element and attribute.
Note: The built-in entity references (&, <, >, " and ') are always expanded during parsing, SAX or DOM. pg. 462.
JDK XPath queries are answered using DOM Nodes, so mismatches here could cause problems. It’s important to set the coalescing feature on so text is handled as expected in XPath.
DOM vs. XPath node
trees
A simple XML document has the same tree of nodes for DOM, XPath
For example, the tree for the XML of the XML RPC example we looked at earlier. The only difference is root node vs Document node at the top.
Document Nodes
We have been drawing
XML trees without a special node at the top, above the root element node. But
both DOM and XPath have such “extra” nodes at the top. Ex 9.2 shows why. It’s
possible (even common) to have comments before the root element in the XML
document, and other things too. So the Document Node (Root node in XPath) is
needed to gather together these nodes along with the root element node to
define the whole document.
Ex 9.2 shows a document node with 4 children:
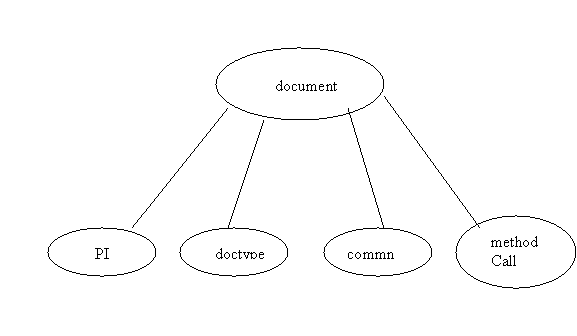
NextType: Element Nodes
Name is QNAME like “book:section”.
URI of n.s. is available
Can have element, PI, comments, text, CDATA children
- attributes are not children !!! because they are not in the official DOM tree
The tree of nodes is fully ordered, but the attributes are not, so perhaps this is why they are not part of the official DOM tree.
Attribute Nodes – not children of Elements and Element is not a PARENT (mutual). This differs from XPATH, where attributes are not children of elements but an attribute has a parent element node. Attributes are “owned” by an element. We can ask for an attribute’s owner via getOwnerElement(), pg. 895. This method used in TestXPath.
When we define a NAMESPACE via an ATTRIBUTE.
DOM just treats this construct as an attribute, but XPATH has a node type for this.
Text Nodes, CDATA Section Nodes
Unlike XPath and SAX, CDATA nodes are (by default) treated separately from non-CDATA text content.
CDATA Example: <greeting> Hi <![CDATA[<happy>]]>!</greeting>
Cases of SAX, XPath, DOM with coalescing on: characters/text node value: Hi <happy>!
Case DOM with coalescing off: 3 nodes, with text as values:
Text node: Hi
CDATA node: <happy>
Text node: !
Node Properties
Note the chart on pg. 450-451. All nodes have a “Name”, but for some types it’s very generic, like “#text” for all text nodes. Elements have their prefixed name as name, but this depends on the prefix, which is not a universal ID.
DOM Parsers
Getting a parser— Xerces is provided in Java 6, via JAXP, as in Example 5.6 and here discussed on pg. 458.
Example 5.6 is
crucial—shows most of the tricks we need.
Skip examples 9.3 and 9.4 because these use non JDK classes. Ex. 9.5 does the same thing with JDK classes.
Ex. 9.5 use DOM parser to check well-formedness. We saw same checking with SAXParser - Ex 6.1.
Setting the DOM
parser configuration, pp. 461-463
Get a DocumentBuilderFactory as in Ex. 5.6 builderFactory, and act on it:
- setCoalescing (Boolean coalescing) p. 461 Good idea for data-centric apps. Treats text the way XPath does.
In fact, we need to set this to allow DOM’s XPath support (used in TestXPath) to return text from CDATA nodes.
Since TestXPath doesn’t do this, CDATA nodes do not show up in the NodeList returned from the XPath query. Should fix it.
- Ignore Comments, p. 462: could go either way
- namespace Aware: p. 463: If using namespaces, should override this questionable default and make this true, at least in theory. The default is inconsistent with SAX, which defaults to namespace processing. However, XPath is very hard to use with namespaces and DOM. There’s no place to put the prefix->URI specification on the XPath. Need to provide a NamespaceContext object. See http://www.edankert.com/defaultnamespaces.html.
Note: we really didn’t need TestXPathIgnoreNS.java: the namespace processing is off by default. The original problem must have been something else. Luckily this edit did no harm. I tried turning namespace processing on, and then got the expected failure to match elements.
- validation (DTD validation) p. 463: note the need for the SAXErrorHandler here.
Xerces (in JDK) can do schema validation, see .DOM Parser: Validating with XML Schema in the J2EE tutorial at Sun.
Get a DocumentBuilderFactory object as in Ex. 5.6
First turn on NS - aware, validation, as above, then schema validation is set up like this— from the same website linked above
Of course, we need a schema associated with the document
- our old way, by linkage in document;
or by putting its filespec in the program:
DocumentBuilderFactory factory =
DocumentBuilderFactory.newInstance();
factory.setNamespaceAware( true);
factory.setValidating( true);
factory.setProperty(
"http://java.sun.com/xml/jaxp/properties/schemaLanguage",
"http://www.w3.org/2001/XMLSchema");
factory.setProperty( "http://java.sun.com/xml/jaxp/properties/schemaSource",
"file:test2.xsd"); // (only
needed if test.xml has no schema linkage itself)
DocumentBuilder builder =
factory.newDocumentBuilder();
Document document = builder.parse( new
Inputsource( "test.xml"));
(Also, there seems to be another way to do this now, with a “Schema” object.)
In SOAP, we have multiple schemas at work, but this can be handled too:
- Set up an array of Strings of URIs for schemas, and pass the array name to setAttribute instead of the one File.
Ex 9.6 use DOM parser to check DTD validity. As with SAX, we need to turn on validity checking, and provide an ErrorHandler as with SAX.
Example 9.6
- checks validity w.r.t DTD
- we could make it do schema validation.
API: page 912 -> Ex 9.6 is using the 3rd version.of parse. In fact the 2 versions of parse for the SAX parser (p.878) and 5 versions for the DOM parser actually covers the same set of possible types of input data streams of XML text, because InputSource is itself a combo of input choices.
Pg..466: discussion of DOM3 Load and Save, but out of date. Use JDK docs, FibonacciEx.java example.
Pg. 468: Node Interface--we already have been using these in XPath processing.
Note that this provides getLocalName() and getNamespaceURI(), which give better name info for Elements and Attributes than getNodeName(), the name listed in Table
Ex. 9.11 Walking the tree: can skip
- double recursion
- first child, next sibling transversal.
Next section: modifying the tree -> good to know it’s possible but don’t worry about it. We can build a tree using appendChild as in Ex. 5.6
NodeList Interface--you have some experience in pa2 on this.
JAXP Serialization: skip
DOM Exception page 486 -> RunTimeException.
This exception should be a checked exception but actually is a RunTime Exception, so IDEs don't remind us to put a catch clause in, but we should anyway!
SAX vs DOM
- They take the same forms of input!
- SAX can handle huge documents (greater than memory size)
- If you only need a little bits of a sizable tree, consider SAX.
- It is easy to find all the nodes of a given tagname with DOM.
- SAX is lean & mean (do all event handers)
- DOM is fat and cushy.
Next time: Midterm
Review