CS639 - Class 02
HW1 is available.
PA1 is coming soon.
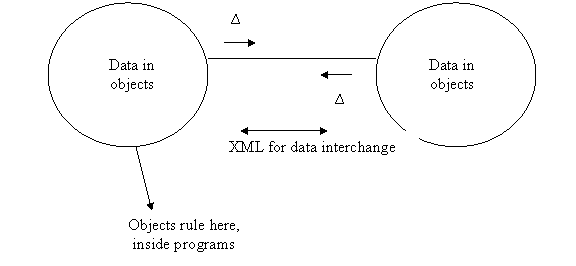
Basic idea: XML is great for getting important data from point A to point B and back. It is not so great for holding data for heavy-duty analysis: that is where databases shine. Luckily we can whisk data in and out of databases and convert it to XML for transport.
Our basic model for this class is the following, where ∆ stands for XML data:
Program A Program B
We can call this idea POX, for plain old XML.
Note that Program A could be Java, program B C# or even C++.
Although XML is great for transporting data, it is not so useful in persistent storage of data. Relational databases still hold the dominant place in persistent data storage. That means there are three data representations in current big programs, in-memory objects, XML, and database tables. We will be considering how to move data between XML and objects. The job of moving data to and from objects and relational tables is tackled in CS636 and CS637. It is also possible to move data directly between database tables and XML—we could cover this topic briefly.
Web Services
The Web Services give us a framework for this data transfer via XML.
- how to find your partner, setup the connection, ...
- we HAVE to understand the connection between program A and program B (this is what we will do in this class today).
We will use tomcat + JAX-WS for SOAP Web Services. tomcat + JAX-RS for RESTful web services.
Note for RESTful web services, in some cases there is no XML in the request, just a HTTP GET. There is XML in the response, however, except in the cases that use JSON instead of XML.
JSON is the new competition to XML, made popular by Ajax. We should look at it at some point.
Network Basics
TCP/IP gives us a TCP stream connection which is the data pipe in the above picture. This type of connection was perfected in '80s.
- underlies many services like remote login, file transfer, web access, email ... with some exceptions ( except NFS and streaming protocols and Voice Over IP - these ones are using UDP/IP).
TCP - provides a two way data pipe from a process on one system to a process on another system (or the same).
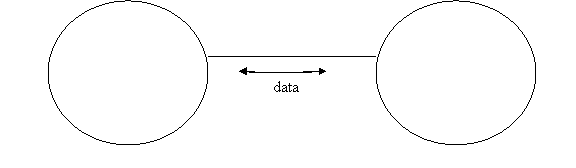
Process A, on host X Process B, on host Y
Process = program in execution, live on the system.
- reliable: no data is corrupted, dropped or reordered.
- flow - controlled.
- it is unencrypted.
- the connection runs all the way across Internet, over many different many networks.
Internet: each "host" directly connected has a unique IP address (32 bits, IPv4, gradually being replaced by IPv6 to allow more ids)
Each host also has a name like "blade42.cs.umb.edu" and this is also unique (the name). There is a mapping between the names and the IP Addresses.
Each system running TCP has and array of TCP "ports". #port = 16 bits (so 64K ports).
Some of these ports have specific services. Ex: port 80 is assigned to HTTP web service, port 21 - telnet ...
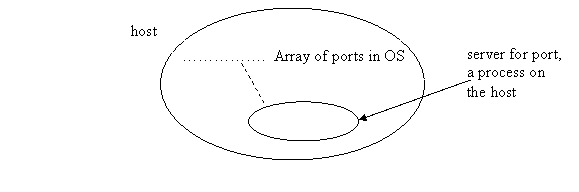
A server (process) can "listen" on a certain port. It has told the OS it is doing so, so when a connection from a client comes in, the OS arranges the active connection from the client to the server.
Ex: web server listens on port 80.
Server processes are long-lived, so they are there when the clients need them. Clients can come and go.
Only one server process can be listening to a certain port on a certain host, at each point in time.
A client is the other end of a potential connection can connect to this port on the server host, thus connecting to the server process. Multiple client processes can run on the same client host, because the client host has plenty of ports, and assigns a different port # for each client end.
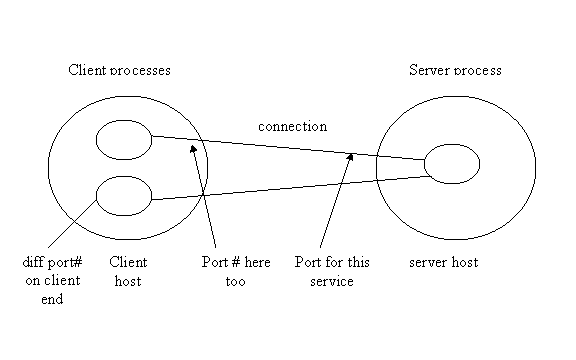
Basic cycle that happens in a Web Service or plain HTTP or other service:
1. Client connects to port X on host Y.
2. Server is listening to that port, accepts that connection and that makes them connected.
3. The Client now sends a request over the connection.
4. The server sends a response back over the same connection.
(3 and 4 can be repeated over and over)
5. Disconnect.
This pattern applies to remote login, file transfer, web access ....
HTTP - the protocol underlying web access, very simple, only one request-response cycle & then disconnect (at least logically).
1 Client connects to port 80 on host Y
2. web server on port 80 accepts.
3. client sends a GET / HTTP/1.0 (1.0 is the version, 1.1 for a real browser)
then there is an optional header.
Then we have one empty line to finish the header.
4. The Web Server sends back the file contents
5. The two parties disconnect.
for example:
if you put the url for our webpage of the cs639 class in the address window of your browser, the browser will get from you:
http://www.cs.umb.edu/cs639
Browser picks out the host name from this, www.cs.umb.edu, converts it to the IP address, and uses port 80, the default web server port. It connects to this host and port and sends the HTTP GET command:
GET
/cs639 HTTP/1.1
Followed by some header information and a blank line to finish it.
It gets back the contents of index.html from that cs639 directory.
(Locally known as /data/htdocs/cs639. The root of our website is /data/htdocs in our distributed filesystem, available from any of our systems.)
The browser knows html, parses the index.html file, finds links for images.
browser does another GET for an image. The web server returns the named image.
There is a link to hw1.html in this index.html file:
<a
href="hw1.html"> hw1 </a>
If user clicks on this link, then the browser does a request for that resource, at URL “hw1.html”. This is relative URL (is asking for a resource in the same directory as its own .html file). The browser remember that index.html is at /cs639, so the browser figures out that hw1.html is at local path /cs639/hw1.html on the server. The server is always given the full local path in the GET (the web server is “stateless”, so is never required to remember what happened previously, as explained more below).
The user clicks on this and the browser does a connect to the same web server as the main page
GET
/cs639/hw1.html HTTP/1.0 (or
1.1)
Then the browser gets this data back from the server and disconnects, and displays this page
Consider the link to forum: <a href="http://www.w3.org/TR/xml-schema-0/">
this is a full or absolute URL. In this case the browser does a connection to
the ip address of the server www.w3.org, on port 80, then does a GET /TR/xml-schema-0/ HTTP/1.1
Other ports can be used for web service, for example 8080 for tomcat, in which case the URL looks like this:
http://example.com:8080/something.
The browser is a "universal client"
The browser knows html, its most basic capability. This is enough to do simple interactions, forms, links, etc. Many websites are set up to only need a browser on the client side.
HTTP is a “stateless protocol”
We give the URL and the browser does the appropriate GET, gets back a resource. Images in HTML -> more GETs in separate connections, where the server could be different. Even if it is the same server, then it is handled separately, in different connections (at least logically.) The server does not have to remember anything. The web server can be "dumb". It does not have to remember the last connection by this user. It doesn't need to know about users at all! Each GET is self-contained. This is why people say that HTTP is a stateless protocol. It does not have to remember things, leading to robustness and universal use. Web servers are so simple to implement that printers and thermostats can have them.
The browser has to be a little smarter. For example, it had to remember that the first index.html came from /cs639, so when it uses the relative URL “hw1.html”, it composes the “GET /cs639/index.html HTTP/1.1”.
A web-based application sometimes has a problem with all these independent request-response cycles and needs to track a user over their many separate HTTP requests. That’s another subject, covered in cs636.
Simple HTML forms (suppose this is on path
/cs639/testform.html in the website on port 11600 on sf08.cs.umb.edu)
<form action="example">
Name:
<input type="text" name="name"/>
School:
<input
type="text" name="school"/>
<input type="submit"/>
</form>
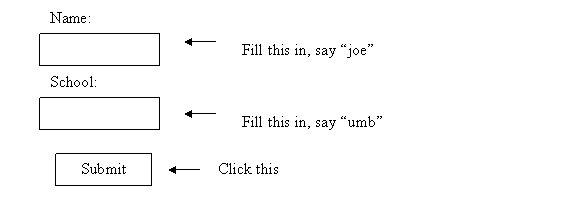
When the user clicks the submit button, the browser sends in a URL with query string to the appropriate server, using HTTP GET or POST. The query string contains the user input parameters and the HTTP response carries back the response to the user, in HTML. This is something like WebServices - a call across the Web.
For example the URL might be http://sf08.umb.edu:11600/cs639/example?name=joe&school=umb.
The browser will show the URL in the address bar (if doing a GET) and break it down as shown before, that is, connect to the IP address for sf08.cs.umb.edu, on port 11600, and then do “GET /cs639/example?name=joe&school=umb HTTP/1.1”
The web server (tomcat) will determine what program is interested in this URL (up to the ?). The program will use the query string to direct its work.
You don’t need to know all the kinds of forms, just text boxes and the idea of the query string going back to the server.
Note that HTML can provide basic UI, but at only a stately pace. To get something buzzing around the screen, you need to have code running on the client side, such as Javascript/Ajax, or a Java applet. We’ll stick to basic UI. This course is mainly about the server side. We will look at JSON, used by Ajax instead of XML.