Class 03 – cs639
HW1 is due next class—questions?
Handout: CS639 Recursive XML Example
PA1 is available. Topic is writing XML from non-XML data.
Google group is formed: you can register with your preferred email by request at Google which I’ll approve.
Using < in character data
Last time we noted that < must be a special character in XML, since it delimits the tags.
If we want a < in character content, we represent the < with the “predefined entity reference” <
This makes & special, so we represent & with &
Since > is naturally paired with <, it also has such a rep >, although it’s not so special as the other two.
Thus if <greeting> holds the string “abc<d>e” we write it in the XML document like this:
<greeting>abc<d>e</greeting>
When an XML parser reads this, it assembles the string “abc<d>e” as element string content.
Question comes up in pa1: is the [] OK in the following, or do we need to quote it somehow?
<paramType>String[]</paramType>
| |
This is a start tag This is an end tag
All this is the element.
“String[]” is the character content of the element—is this [] OK for well-formed XML?
We can find out by using the XML 1.0 Standard, linked from the course web page under “Resources”
Using the XML Standard—it’s readable!
It’s in HTML, with effective use of links.
The rules are written in EBNF, covered in Sec. 6—we went over them.
[abc] a or b or c
[^abc] not (a or b or c)
[^<&]* a sequence of 0 or more occurrences of chars, each not a ‘<’ or ‘&’
…
To determine if “String[]” is valid content of the element—
1. find the element definition:
element::= EmptyElemTag | Stag content Etag
|
Our question is
in here
2. follow the link from content to its definition:
content ::= CharData?((element | Reference | CDSet | PI | Comment) CharData?)*
| Reference = entity ref (incl. < & etc.) or char ref (&x38;, etc.)
| ß----------------------------------------------------------------------------------à
| All this can be not-there because of the *
In here, find its rule--
CharData ::=[^<&]*-([^<&]*’]]>’[^<&]*)
[^<&]* is a regular expression of EBNF
[^<&]*’]]>’[^<&]*
sequences of chars, each not < or &, with ‘]]>’ somewhere
within it.
CharData: sequences of chars, each not a ‘<’ or ‘&’, and also not containing any subsequences of the form ‘]]>’
Element content abc<d>e (example above) parses as CharData Reference
CharData Reference CharData
by the rule above, since < and > are References, leaving abc, d, and
e as simple CharData
strings.
So ‘String[]’ is OK as CharData, and all oldstyle Java types are too – but what about generics such as Pair<String>. This needs the < escape for ‘<’. Can also use > for the > sign, for symmetry.
<paramType>Pair<String></paramType>
(or we could use abc<d>e, but it looks funny. Only < really needs quoting in element content)
(or we could use abc&d>e, that is, using the “character reference” & for <, using its character code.)
Attribute values also
can use <, etc., need
" or ' in
some cases
Similar rules about quoting > and & hold for attribute values, but there quotes are used as delimiters, and thus need quoting if the same quote is used in the string within the delimiters. " '
Luckily, with the choice of two quotes, currency=”USD” or currency=’USD’, we usually don’t need these.
XML as sequence of Unicode characters, in UTF-8 or other encoding
The text of an XML document (markup and content) has even more basic requirements set out on pg. 20 of text and near the start of the standard. Basically, an XML document is a sequence of Unicode characters, with some (strange) characters disallowed. Unicode is “encoded” into 8-bit bytes by well-known mappings. Some characters (ex. Asian chars) take multiple bytes.
The default encoding for XML is UTF-8, which matches ASCII across the 128 ASCII characters (codes 0-127). Many examples in the text have encoding=”ISO-8859-1” in the XML declaration. This is the “Latin-1” character set that has more than 128 characters (but less than 256, so fits in 8 bits, and again matches ASCII for codes 0-127.) We should come back to this later.
End of lines (eols): It’s OK to store XML using LF (UNIX 1-byte eol) or CRLF (Windows 2-byte eol), but processor is expected to remove CR from CRLF as first step, so in programs, eols appear as LFs, and in fact no CRs are left, since singleton CRs are replaced with LFs.
XML Coverage
We’ll cover carefully:
- elements
- attributes
- comments
- XML declarations
We will worry less about:
- PIs
- Entities (except the built-in entities like < needed to make XML work)
- Namespaces – related to integration of XML to multiple sources. (we will cover this later)
Looking at the
handout on Recursive XML:
Note JSON can’t do recursive data structures.
A section has a title, followed by <p>, then possibly a figure (or figures?), the possibly sections.
The figure has a title, then an image. Every time you look at an image, you have a source attribute.
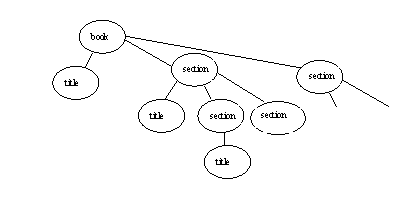
Picture of tree of elements: book at top, children below, sections within sections, …
Partial picture:
The DTD, schema: specify structure patterns.
The DTD entry for an element has form:
<!ELEMENT name contentspec>
The content spec can be: (#PCDATA) or EMPTY or ALL or a “content model” describing how the child elements are organized. There is another possibility for “mixed content” that we can look at next time.
This content model can be a sequence of comma-separated,
decorated element tagnames, with parentheses for
grouping, and *, +, and ? indicating
how many can show up. The whole thing is inside parentheses.
On the handout , we have:
<!ELEMENT section (title, p, (figure, p)*, section*)>
The easiest content spec is just (#PCDATA), i.e., CharData.
<!ELEMENT title (#PCDATA)>