CS639 Class 05 XPath,
more on UTF-8, TestXPath
pa1a due Thurs. night: questions?
Start on XPath
Basics
Read the first 3 pages of Chap. 16 for now.
XSL uses XPath to locate data in XML input. So do other tools.
XPath is a simple query language for XML. It is sort-of equivalent to SQL for DB data, if SQL could only read tables and return row ids, not the actual data. It’s like the first part of a SQL query where the query processor locates the results in the data.
XQuery is more powerful, can compose new XML rather than just find things in XML. It really is like SQL queries. Not widely used however.
Look at the tree of element of elements (other things as well next time)
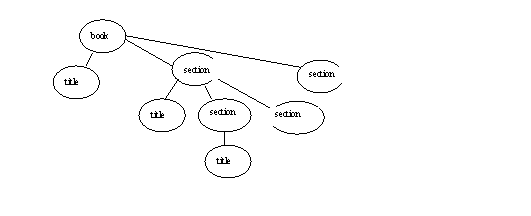
Idea of path: /book/section/title – path to the element down from the root
XPath Query: find the nodes that match a path description
1) /book/section/title query has results: 2 nodes, the 2 title elements of the two top level sections
2) /book/section/section/title as query result has maybe 4 titles of second-level sections.
Find all title elements, user XPath //title
The JDK has XPath support. It can return “nodes” to your program, one for element (or other thing) it locates in the XML. I’ve written a little program TestXPath that will run XPath queries on a given XML file, like this:
java TestXPath
book.xml
Enter XPath
expression:
/book/section <--you enter the XPath expression
Using file book.xml, xpath = /book/section
Report of node.toString's
and paths of all hits:
[section:
null] /book/section
[section:
null] /book/section
Given: well-formed XML document, after resolution of entity references like < etc. (and CDATA sections, but we’re ignoring them for now).
No DTD or schema is needed, so we are working with the document itself. Great tool for schema-less XML. Without a schema, you have no assurance that the structure is stable, so XPath is your best bet for finding answers even if a new level has been added to the tree.
Ex from last time: local weather info in XML at:
http://www.weather.gov/xml/current_obs/KBOS.xml (Logan airport)
First line of doc shows char encoding is ISO-8859-1, surprising, old-fashioned.
We can use XPath to dig out particular info:
/current_observation/temp_f or /temp_c this would be the XPath for F or C as temperature.
In fact, the filename argument for TextXPath can take a URL
Try
java
TestXPath http://www.weather.gov/xml/current_obs/KBOS.xml
Enter
XPath expression: //temp_f
Using
file http://www.weather.gov/data/current_obs/KBOS.xml, xpath
= //temp_f
Report
of node.toString's and paths of all hits:
[temp_f: null] /current_observation/temp_f
Content
of first hit:
42
to get the current Boston temperature in F
We consider the XML as a tree of elements, attributes, etc., all called nodes. Note that the XML spec itself never talks about nodes, just elements, attributes, …, and CharData, entity refs, etc.
Consider another kind of object in XML tree rep: text node, in boxes here: In simple cases, the contents of a text node is just the character data contents (with <, not < etc.) of an element.
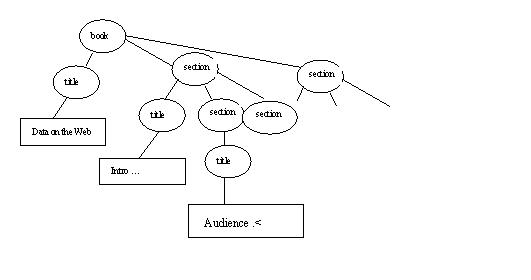
Here the first section title element has been changed to <title>Audience <</title> to give an example of an entity in element content. The entity is resolved in the XPath text node. Note the < in the text node, not <
(In fact, the bits of “white space” between element tags provide additional text nodes, but let’s not worry about this yet.)
Look at an element
/book/section/title – path to the element
XPath: find the nodes that match a path description
3) /book/section/title query has results: 2 nodes, the 2 title elements of the two top level sections
4) /book/section/section/title as query result has maybe 4 titles of second-level sections.
Find all title elements, user XPath //title
Find the first section of book:
/book/section[1] yields one section element that is the first section of the book.
Document order and the XPath node tree
Note that the child nodes of a certain node in the XPath node tree are in a certain order, which makes the whole tree of elements ordered. The resulting ordering of elements by depth-first traversal is known as document order, and follows the order of elements in the textual XML. The other nodes in the XPath node tree are in all cases attached to a certain element. The order of attributes for an element is not fixed in the XPath node tree, so we say an element node has a set of attribute nodes. This is alluded to on Harold, pg. 759, first paragraph. So the whole collection of nodes is not fully ordered, but is still referred to as in “document order” following the depth-first traversal of the node tree.
For each element node, attribute nodes precede child element nodes, as in the textual XML. Text nodes for an element node (vs. child nodes) are in the order determined by the textual XML.
/book/section[title = “Introduction”] yields one section element that has a title = “Introduction”
Here the XPath before the [] selects all the top-level section nodes. For each of these, the [title …] is a predicate filtering out some of those nodes. The “title” inside the [] is the relative XPath from an already selected node (i.e. a top-level section node) and it gets to corresponding title of that section node, which needs to match the “Introduction” string to pass the predicate test. The result is a section node.
See Examples on pg 754 on Weather Data. Here is a partial graph—you need to add to it to see everything for the queries. Note that this is quite different from the weather data we looked at last time.
16
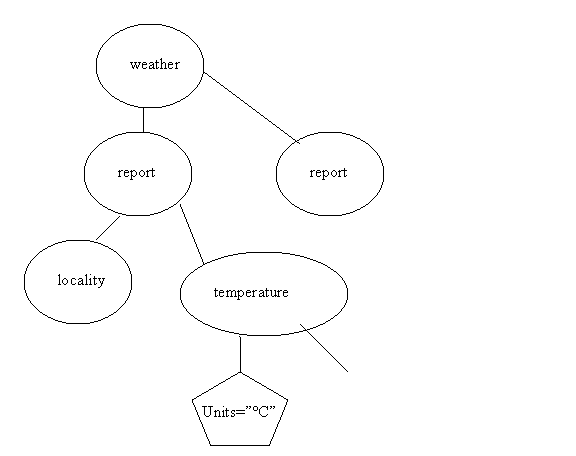
/weather/report[1] 1 report node, Block I.
/weather/report/temperature 2 temperature nodes
/weather/report [locality = “
/weather/report [locality = “
This gives you direction node of the wind node for Block Island’s report.
Localities where wind is NE:
/weather/report[wind/direction = “NE”]/locality
localities having the same
temperature as
/weather/report/[temperature =
/weather/report[locality=”
/weather/report/[temperature < 20 and wind/direction=”NE”]
or
/weather/report/[temperature < 20]/wind[direction=”NE”]
Query on attributes: find temperature elements with units attribues:
/weather/report/temperature[@units]
All temperature nodes under report at any level--
/report//temperature
All elements: //*
All attributes //@*
All attributes named units: //@units
All textnodes: //text()
All textnodes of temperature elements: //temperature/text()
The weather xml of pg. 754 is encoded in ISO-8859-1. It could be in UTF-8, the default encoding for XML.
CharSet: ISO-8859-1(also known as Latin-1) can encode western European languages, 8 bit code, is the default encoding for HTML. UTF-8 (compressed form of Unicode), is the default encoding for XML
Let’s look at the non-ASCII character that shows up here (degree sign):
To convert weather.xml to UTF-8, we would need to replace all the degree
signs in it from their Latin-1 code (1 byte) to their UTF-8 coding (two bytes).
Degree sign ° in LATIN-1 = 0xb0 = binary 1011 0000 (high bit on in byte)
Note that 00b0 > 007f
Code 0x7f (binary 0111 1111) is the highest ASCII code.
Unicode for this char is 0x00b0 with two more binary zeroes on the left to make 18 bits.
UTF-16, used by Java: code = 0x00b0
Recall that the UTF-8 representation of an ASCII char is just the single 8-bit ASCII code (with high bit off).
An important fact
about UTF-8: High bits of bytes are flags for non-ASCII chars and their
multi-byte codes
In UTF-8, the only bytes with high bits off are the ones representing ASCII codes. All other chars have at least 2 bytes in their UTF-8 representation, each with the high bit on.
What is the UTF-8 representation of this ° char? It can’t be 00 b0, because the high bit is off in the first byte. It is two bytes long, and both bytes have high bit 1 to mark it a non-ASCII char. We don’t care what the exact bit pattern is, since we can always use tools to create these codes. In fact the UTF-8 encoding is the sequence of two bytes 0xc2 0xb0.
For more information on how to encode any Unicode char, see Character Encodings (1 page).
How to convert
Latin-1 to UTF-8
On Linux: iconv
--from-code=ISO-8859-1 --to-code=UTF-8 weather.xml>weather2.xml
However, after this the first line still says encoding=ISO-8859-1, You can use emacs (or vi?) on sf08 to change this.
Our Linux host, sf08, has a UTF-8 environment: use the “locale” command to see this.
Displaying UTF-8 text from sf08 on your screen, if logged in from home:
If you are using putty, you can change its settings to display UTF-8 properly:
Change Settings>Window>Translation> Received data assumed to be in which character set: UTF-8
With this setting, the original weather.xml (in Latin-1) is displayed with block chars where degree signs should be.
Creating new UTF-8 text: Word may be the best choice, with its Insert>Symbol pop-up display of Unicode characters to choose from. Eclipse doesn’t seem to have a pop-up to show possible characters to insert, but it properly displayed both versions of the file, that is, the degree sign looks good for both weather.xml and weather2.xml. It must be looking at the first line and seeing the encoding= value.
On Windows: Word (Word 2007) can convert Latin-1 XML to UTF-8 (or other encoding) if you are very careful. Read weather.xml as given in $cs639/xpath or from Harold’s online book, and the “Save as..” and choose Web Options> Encoding> UTF-8. Choose “Word2003 XML format”. The resulting file will have proper <?xml...?> and converted character codes, but poor formatting (mostly all on one line.) I used eclipse to reformat it, and the final version of the file as UTF-8 XML is in $cs639/xpath/weather2.xml, along with the original weather.xml in Latin-1 encoding.
I couldn’t get eclipse to convert XML from Latin-1 to UTF-8.
We’ll see that with HTTP, we can deliver text along with attributes such as charset, so the end user doesn’t have to know the details and set things up.
Final note on this: It is important to realize that some characters have multi-byte UTF-8 representations. We can’t just read a byte of UTF-8 and expect it to be a full character. All multi-byte representations have the high bit on in all of its bytes. If a high bit is off in a byte, that’s a single-byte UTF-8 representation of an ASCII char.
Back
to XPath.
XPath processing program – TestXPath program, in $cs639/xpath, linked from the class web page under Resources, XPath, along with the W3C Recommendation (“standard”)
Ex: java TestXPath clocks.xml
Enter xpath expression: …
See README
displays
- all the paths of selected nodes.
- string value of the first node selected
o See Table 16.1 of Harold, pp. 757-758, for definition of “string value”
We don’t know how to parse XML yet, but we can use the tools in JDK. Look at TestXPath.java and you can see how it gets its data and convert that to get the data from the InputStream provided by the URL object.
In TestXPath.java, we see:
new InputSource(xmlURL) // xmlURL is args[0], the filename/URL of the XML file, from the command line.
We look into jdk docs to tell us what an InputSource object is, and find it is managing input for XML parsing.
The XPath code reads XML input from this input.
This code parses the XML, with knowledge of the XPath & picks out the matching data. It builds a “DOM tree” of nodes in memory. It returns info on the resulting nodes to the program and the program prints out info that we were looking for.
In particular, we see in TestXPath.java that the nodes come back in a NodeList object:
See JDK documentation for the NodeList. In TestXPath, we see a NodeList named nodes. Then
nodes.item(i) = individual Node.
For a single Node node:
node.getNodeType() – it will tell you if it is an ELEMENT_NODE, …
node.getNodeName() and so on.
This way of using XPath is a lot easier than having the program actively involved in the XML parsing. This is the best way to do simple information retrieval from XML that has no schema, and is competitive for XML that does have schema.
Now we are done with Chapter 1, plus intro to XPath. Next: Chap. 2