CS639 – class 14
After Midterm: REST
Web Services
Read Webber et al, Chap 1-3: background, we’ve covered the underlying Web technology already.
Also, Chap 11 on SOAP vs REST, etc.
Then start studying Chap 4, the CRUD service for coffee orders, first real example. I’ll supply a Java project for this.
Last time: intro to
DOM Programming:
Ex 5.6: Reading and writing no-namespace XML
Ex. 10.5 Writing a document with a default namespace
Handout: Ex. 10.5 edited to write a document with a non-default namespace
Handout: Program to read XML with a namespace and determine that namespace by using rootNode.getNamespaceURI(). (This does assume the namespace is set up at that root element.)
There is another difference between Ex 5.6 and Ex. 10.5: two ways to create the top part of the XML tree. In Ex 5.6, create a Document node, then add a root Element to it. In 10.5, create the Document and root Element together in one call.
Then we started looking at the data models for DOM and XPath
DOM Nodes vs. XPath
Nodes
For DOM: 12 kinds of Nodes
For XPath: 7 kinds of Nodes.
See pg. 760 for discussion of XPath vs. DOM
|
DOM node |
Corresp. XPath node |
|
Document node |
Root node |
|
Element node |
Element node |
|
Text node (includes CDATA text if the coalescing feature is on) |
Text node (but includes CDATA, entity text) |
|
Attribute node |
Attribute node |
|
PI node (skip) |
PI node |
|
Comment node |
Comment node |
|
CDATA node (missing if coalescing is on) |
--- Absorbed into text node |
|
Document type node |
|
|
Notation node (skip) |
|
|
Document fragment node (skip) |
|
|
Entity node (skip) |
--- Resolved entities are in Text nodes |
|
Entity Reference node (skip) |
|
Note: Namespace Nodes are in the XPath data model but not in DOM (more below). In DOM, namespace information for nodes is available via Node methods getNamespaceURI and getPrefix. See pg. 904. This setup is convenient for programmers—DOM has digested the whole document and determined from the various xmlns=... attributes what NS pertains to each element and attribute.
Note: The built-in entity references (&, <, >, " and ') are always expanded during parsing, SAX or DOM. pg. 462. These are the only entity references we’re covering.
JDK XPath queries are answered using DOM Nodes, so mismatches here could cause problems. It’s important to set the coalescing feature on so text is handled as expected in XPath.
DOM vs. XPath node
trees: we’ll assume DOM has coalescing feature on
A simple XML document has the same tree of nodes for DOM, XPath
For example, the tree for the XML of the XML RPC example we looked at earlier. The only difference is root node vs Document node at the top.
Document Nodes (pg. 442)
We have been drawing
XML trees without a special node at the top, above the root element node. But
both DOM and XPath have such “extra” nodes at the top. Ex 9.2 shows why. It’s
possible (even common) to have comments before the root element in the XML
document, and other things too. So the Document Node (Root node in XPath) is
needed to gather together these nodes along with the root element node to
define the whole document.
Ex 9.2 shows a document node with 4 children:
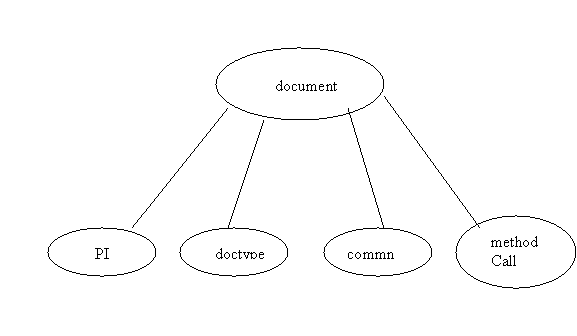
Element Nodes (pg. 443)
Name (returned by Node’s getNodeName) is QNAME like “book:section”.
URI of n.s. is available
Can have element, PI, comments, text, CDATA children
- attributes are not children !!! because they are not in the official DOM tree
The tree of nodes is fully ordered, but the attributes are not, so perhaps this is why they are not part of the official DOM tree.
Attribute Nodes – not children of Elements and Element is not a PARENT (mutual). This differs from XPATH, where attributes are not children of elements but an attribute has a parent element node. Attributes are “owned” by an element. We can ask for an attribute’s owner via getOwnerElement(), pg. 895. This method used in TestXPath.
When we define a NAMESPACE via an ATTRIBUTE, DOM just gives it an attribute node, but XPATH has no attribute node for it.
XPath Namespace Nodes
XPath has namespace nodes, not for where the namespace is attached by an attribute, but to mark that an element (or attribute) has a namepace in scope. So the XPath tree of nodes is littered with these namespace nodes, one for each element in scope for each namespace. Deep in the tree an element may easily have multiple namespace nodes as children. See example, pp. 758-759. XPath also is holding the info on the actual namespace of each element and attribute, and these can be accessed by XPath functions (see pg. 758).
Text Nodes, CDATA Section Nodes
Unlike XPath and SAX, CDATA nodes are (by default) treated separately from non-CDATA text content.
CDATA Example: <greeting> Hi <![CDATA[<happy>]]>!</greeting>
Cases of SAX, XPath, DOM with coalescing on: characters/text node value: Hi <happy>!
Case DOM with coalescing off: 3 nodes, with text as values:
Text node: Hi
CDATA node: <happy>
Text node: !
Node Properties: Node
is the base class, Element, Attr, etc are subclasses of Node
Note the chart on pg. 450-451. Need to relate this to the Node API on pg. 904. All nodes have a “Name” (Node’s getNodeName()), but for some types it’s very generic, like “#text” for all text nodes. Elements and Attr’s have their prefixed name as name but this depends on the prefix, which is not a universal ID. You can call getLocalName() and getPrefix() and getNamespaceURI() to get the individual parts of the name.
Node value: (column Value on pg. 450, getNodeValue() in Node API): is null for elements, unlike the “string value” for XPath elements, which give you all the “content” below the element in the tree. There is another Node method, not listed on pp 904-905, getTextContent() which can deliver the content at and below this element (not incl. comments). Suggest adding this method to pg. 905.
Node Parent, Children (columns on pg. 450, getParentNode, getChildNodes, also getFirstChild etc, in the Nod API) for the DOM tree connections. Note there is an error here listing Element as parent of Attr. Need to use Attr’s getOwnerElement to find the element of an attribute.
DOM Parsers
Getting a parser— Xerces is provided in Java 6, via JAXP, as in Example 5.6 and here discussed on pg. 458.
Examples 5.6 and 10.5
are crucial—show most of the tricks we need.
Skip examples 9.3 and 9.4 because these use non JDK classes. Ex. 9.5 does the same thing with JDK classes.
Ex. 9.5 use DOM parser to check well-formedness. We saw same checking with SAXParser - Ex 6.1.
Setting the DOM
parser configuration, pp. 461-463
Get a DocumentBuilderFactory as in Ex. 5.6 builderFactory, and act on it:
- setCoalescing (Boolean coalescing) p. 461 Good idea for data-centric apps. Treats text the way XPath does.
In fact, we need to set this to allow DOM’s XPath support (used in TestXPath) to return text from CDATA nodes.
Since TestXPath doesn’t do this, CDATA nodes do not show up in the NodeList returned from the XPath query. Should fix it (will discuss this next time.)
- Ignore Comments, p. 462: could go either way
- namespace Aware: p. 463: If using namespaces, should override this questionable default and make this true. As discussed last time, this default is inconsistent with SAX, which defaults to namespace processing. - validation (DTD validation) p. 463: note the need for the SAXErrorHandler here.
Xerces (in JDK) can do schema validation, see .DOM Parser: Validating with XML Schema in the J2EE tutorial at Sun.
Get a DocumentBuilderFactory object as in Ex. 5.6
First turn on NS - aware, validation, as above, then schema validation is set up like this— from the same website linked above
Of course, we need a schema associated with the document
- our old way, by linkage in document;
or by putting its filespec in the program:
DocumentBuilderFactory factory =
DocumentBuilderFactory.newInstance();
factory.setNamespaceAware( true);
factory.setValidating( true);
factory.setProperty(
"http://java.sun.com/xml/jaxp/properties/schemaLanguage",
"http://www.w3.org/2001/XMLSchema");
factory.setProperty(
"http://java.sun.com/xml/jaxp/properties/schemaSource",
"file:test2.xsd"); //
(only needed if test.xml has no schema linkage itself)
DocumentBuilder builder =
factory.newDocumentBuilder();
Document document = builder.parse( new
Inputsource( "test.xml"));
Also, there is another way to do this now, with a “Schema” object. New with JAXP 1.3, since book was written. This newer way also allows us to check the validity of a DOM tree already in memory, not just one on the way into memory with parsing. If interested, see IBM doc.
In SOAP and REST, we have multiple schemas at work, but this can be handled too:
- Set up an array of Strings of URIs for schemas, and pass the array name to setAttribute instead of the one File.
Ex 9.6 use DOM parser to check DTD validity. As with SAX, we need to turn on validity checking, and provide an ErrorHandler as with SAX.
Example 9.6
- checks validity w.r.t DTD
- we could make it do schema validation.
DOM parser API: page 912 -> 5 versions of parse! Ex 9.6 is using the 3rd version.of parse. In fact the 2 versions of parse for the SAX parser (p.878) and 5 versions for the DOM parser actually cover the same set of possible types of input data streams of XML (URL, InputStream, Reader), because InputSource is itself a combo of input choices. The File version for DOM isn’t really a new input type because getting data from the file involves an InputStream. Recall that it’s good to specify a URL for the input in addition to an InputStream or Reader so the parser can interpret relative URLs in the document.
Pg..466: discussion of DOM3 Load and Save, but a non-Sun version. Use JDK docs, FibonacciEx.java example.
Pg. 468: Node Interface—same as on pg. 904-905.
Ex. 9.11 Walking the tree: There’s no Node iterator across the tree in the Core DOM, so we need to do it by multiple steps as shown here and also (using NodeList) on pg. 482-483
NodeList Interface--you have some experience in pa2 on this.
JAXP Serialization: skip
DOM Exception page 486 -> RunTimeException.
This exception should be a checked exception but actually is a RunTime Exception, so IDEs don't remind us to put a catch clause in, but we should anyway!
SAX vs DOM
- They take the same forms of input!
- SAX can handle huge documents (greater than memory size)
- If you only need a little bits of a sizable tree, consider SAX.
- It is easy to find all the nodes of a given tagname with DOM.
- SAX is lean & mean (do all event handers)
- DOM has XPath support, a huge advantage—more on this next time
Next time: look again at XPath, then on to REST.
(The XPath examples are already available in $cs639/xpath. See its README if interested.)