Project FRESH: Fair and Efficient Slot Configuration and Scheduling for Hadoop Cluster.
In a classic Hadoop cluster, each job consists of multiple map and reduce tasks.There are multiple task slots: map slots just for map tasks and reduce slots just for reduce tasks. Each task slot can process only one task at any given time. We argue that such static settings cannot yield the optimal performance in makespan for a batch of jobs with varying workloads. In addtion, fairness for each job is not accurately defined for this two-phase MapReduce process in prior work. More specifically, there are two problems in the native Hadoop:
- Static slot configuration: by default, Hadoop uses fixed number of map slots and reduce slots throughout the lifetime of a cluster. However, for jobs with different workloads in the map/reduce phase, the slot configuration for the best performance in the execution time of each job is different.
- Fairness: Fair Scheduler considers fairness separately in map and reduce phase in the execution of jobs which may cause starvation of resource consumption for some jobs in the overall execution.
Our Solution:
We propose FRESH to achieve fair and efficient slot configuration and scheduling for Hadoop cluster. Our main target is to improve the makespan performance as well as the fairness for each job. First, FRESH allows a slot to change its type dynamically after the cluster has been started. Second, FRESH assigns the appropriate tasks to slots.
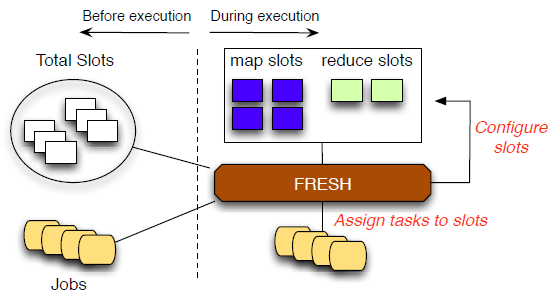
There are three new modules are created in FRESH. When a slot finishes its task:
- Workload Monitor assigns the idle slot to be map slot or reduce slot.
- Fairness Monitor calculates the overall fairness of each job and choose a task of the job with the least overall fairness.
- Slot Assigner assigns the chosen task to the idle slot for execution.
The implementation of FRESH is based on Hadoop version: 0.20.2. Two modulers are created in JobTracker: one updates the statistical information such as the average execution time of a task and estimates the remaining workload of each active job, the other is designed to configure a free slot to be a map slot or a reduce slot and assign a task to it.
The Evaluation:
-
Purdue MapReduce Benchmarks Suite
- Benchmarks: Inverted Index, Classification, Histogram Rating, Word Count, Grep
- Input files: 8GB wiki category links data, 8GB Netflix movie rating data
- Hadoop Cluster
- m1.xlarge Amazon EC2 instances
- 1 master node and 10/20 slave nodes
- 4 task slots on each slave node
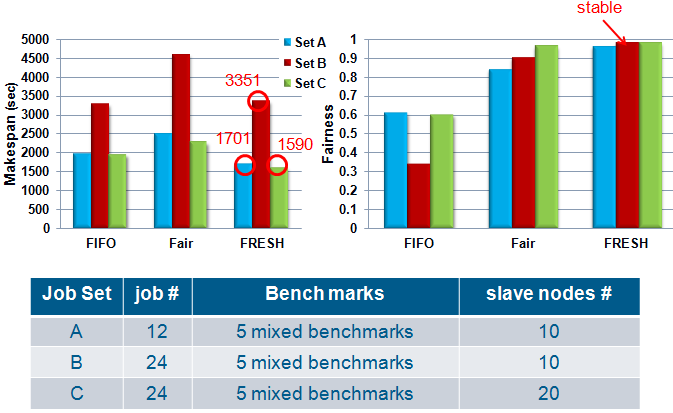
- Makespan: the completion length of a set of MapReduce jobs.
- Fairness: We use Jain's Index to indicate the overall fairness of all jobs.
- F(T) is bounded in the range of (0,1].
- Higher value means better fairness.
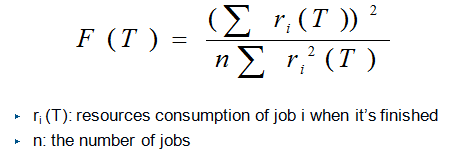
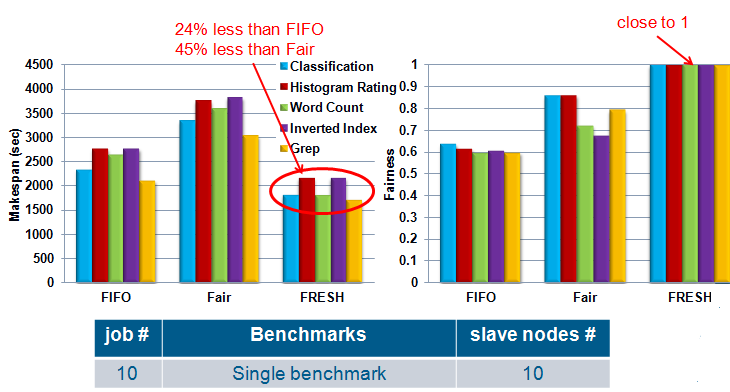
- Single Benchmarks:
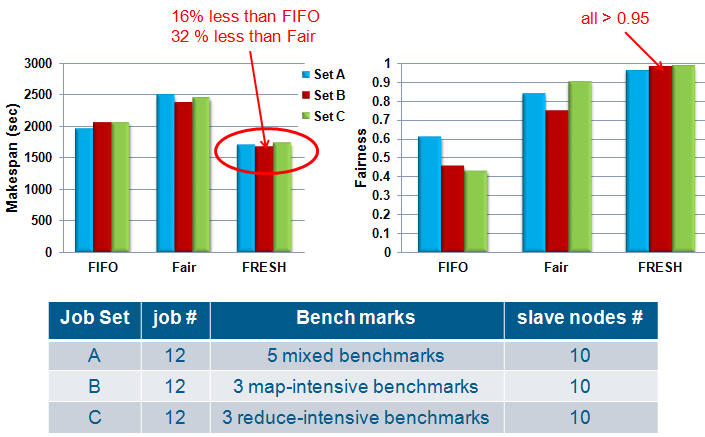
- Mixed Benchmarks:
- Scalability:
Publication :
FRESH: Fair and Efficient Slot Configuration and Scheduling for Hadoop Cluster
[CLOUD'14 ]The 7th IEEE International Conference on Cloud Computing, Anchorage, AK, June 2014